Foveated Pipeline for AR/VR Head-Mounted Displays
Foveated Pipeline for AR/VR Head-Mounted Displays
Foveated Pipeline for AR/VR Head-Mounted Displays
In order to deliver a great visual experience with standalone augmented-reality or virtual-reality head-mounted displays (HMDs), the traditional display rendering pipeline needs to be re-thought to best leverage the unique attributes of human visual perception and the features available in a rendering ecosystem. The foveation pipeline introduced in this article considers a full integration of foveation techniques, including content creation, processing, transmission, and reconstruction on the display.
by Behnam Bastani, Eric Turner, Carlin Vieri, Haomiao Jiang, Brian Funt, and Nikhil Balram
THE visual experience that current augmented-reality/virtual-reality (AR/VR) headsets deliver is significantly below what we perceive in the real world, in every respect – resolution, dynamic range, field of view (FOV), and contrast. If we attempted to render content that was close to our visual system’s capability of approximately 210 degrees horizontal and 150 degrees vertical FOV at 20:20 visual acuity, with a refresh rate well above the limit of flicker perception, we would need to deliver over 100 Gb/s to the display. The rendering rate becomes even larger when we consider generating a light field by using multiple focal planes per frame or multiple angular pixels per spatial element. These rates would be extremely difficult to achieve on mobile headsets with strict thermal limits restricting the available compute power of the system on chip (SoC) and the bandwidth of the link to the panels. In this article, mobile headsets are defined as systems that are self-contained in terms of computation and power, with all the compute being done by a main SoC similar to the application processor (AP) SoC used in a smartphone, and all the power coming from an on-board battery.
An elegant and practical solution is possible if we consider some core attributes of the human visual system when designing the pixel-generation pipeline. In particular, the primary image-capture receptors in the retina are concentrated in a narrow central region called the fovea. The image that is acquired at each instant produces high information content only in the foveal region. Using this attribute in the processing path enables the creation of a much more practical approach called the “foveation pipeline.”
In this article we present a complete foveation pipeline for advanced VR and AR head-mounted displays. The pipeline comprises three components:
1. Foveated rendering with focus on reduction of compute per pixel.
2. Foveated image processing with focus on reduction of visual artifacts.
3. Foveated transmission with focus on reduction of bits transmitted to the display.
Figure 1 shows an overview of the foveated pipeline with these three major operations highlighted. The foveated rendering block includes a set of techniques with the aim of reducing operations per pixel. The foveated content is passed on to the foveated image-processing block, where operations focus on enhancing the visual perception of the overall system but in a foveated manner. These operations include correction for lens aberration or lighting estimation in augmented reality. The last block, foveated transmission, is where optimizations are done to transmit the minimum number of bits per pixel between the SoC and the display. Some of the transmission operations may benefit significantly when they are integrated with operations done at the display timing controller (TCON).
For each step, we have developed a set of techniques that consider both human visual perception and feasibility in current or upcoming mobile platforms.
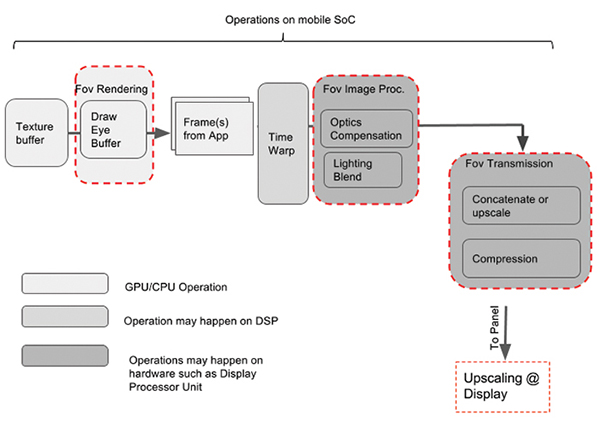
Fig. 1: The foveation pipeline for standalone AR/VR headsets shows operations performed on various compute subsystems of a mobile application processor SoC.
Foveated Rendering
The human visual system has an elegant and efficient information-processing architecture. The eye’s “image sensor,” the retina, has two major types of receptors that capture light in the visible spectrum – rods and cones.1 Rods are primarily used for vision in low light conditions and provide no color information. They are concentrated in the periphery and have limited spatial-discrimination abilities but are very sensitive to temporal changes. Cones are used for daylight viewing and provide fine spatial discrimination as well as a sense of color. They are present throughout the retina, but are concentrated in a narrow central region spanning only a few degrees, called the fovea. Figure 2 shows the distribution of rods and cones across the retina.
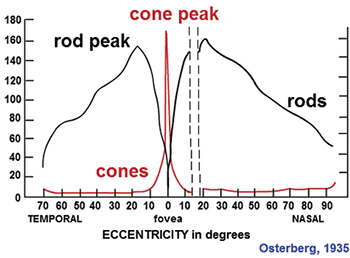
Fig. 2: Rods and cones are distributed across the retina.1 The receptors (cones) used for daylight viewing and the sensation of color are concentrated in a narrow region called the fovea.
The sensation of having a high-resolution, full-scene representation like the one shown in Fig. 3 is produced by the eyes continuously scanning the scene through rapid eye movements called saccades.2 At any specific instance, the front end of the human visual system is only capturing a high-resolution image over a few degrees of visual field. Hence, the optic nerve, the “information bus” that brings image data from the retina to the visual cortex for processing, is estimated to have a bandwidth of only ~10 Mb/s.3

Fig. 3: This example of high-resolution content was rendered at constant high-spatial resolution.
This highly data-efficient “foveated” capture is the inspiration for efficient ways of rendering for head-mounted displays. Through the use of techniques called “foveated rendering,” the user’s eye movements are employed to deliver high resolution only for the specific region of interest.
Foveated rendering can take advantage of the radial drop-off in visual acuity to improve the performance of the rendering engine by reducing spatial, or bit-depth, resolution toward the periphery. The location of the high-acuity (HA) region needs to be updated to present high-resolution imagery to the fovea to preserve the perception of rendering a constant high-resolution image across the display. A delay between saccades and the updating of content on the display may result in perceptual artifacts.
Figure 4 shows an example of the results produced by a foveated rendering system, where content in the fovea, usually around 5 degrees as shown in the yellow circle, is rendered at high-spatial resolution, and content in the periphery is rendered at low resolution. Since the spatial acuity of human perception drops continuously outward from the fovea, one can represent the gradual drop in resolution using multiple low-acuity regions.

Fig. 4: This example uses two layers of foveation -- one rendered at high resolution (inside the yellow circle) and one at lower resolution (outside the circle).
There are two approaches to address the requirements of saccades in foveated rendering –“dynamic foveation” and “fixed foveation.”
Dynamic foveation uses eye tracking to measure gaze location and then adjusts the location of the HA region accordingly. Higher accuracy and lower latency in the eye-tracking sensor allows for the same visual quality to be achieved with a smaller HA region. The smaller the HA region, the greater the reduction in overall rendering computational costs.
Fixed foveation considers the optical performance of the HMD lenses and their impact on perception of HMD display acuity. For the fixed-foveation method, the rendered spatial resolution tries to match the optical performance of the HMD lens. For this method, the HA region is typically larger than in the case of dynamic foveation, and its rendering cost is higher. By not requiring an eye-tracking sensor, this approach is compatible with all existing devices. Application developers may select a more
aggressive foveation region than what the HMD acuity is, thus resulting in smaller HA regions and better compute savings. Heuristics such as a foveation heat map over time may be used to adjust the foveation region and the resolution of the peripheral region.
In practice, existing dynamic foveation techniques tend to be more conservative in their foveation than our human visual system. Part of the issue is that current headsets aren’t starting out as a perfect visual system to begin with. Current commercial headsets are resolution-limited and present details comparable to 20:90 acuity on a standard eye chart. From such a reduced starting point, aggressive foveated rendering in the periphery is easily noticeable. Additionally, these headsets have an FOV much narrower than the human visual system, typically delivering 90 degrees horizontal, whereas humans can see in excess of 200 degrees horizontal.
However, the long-term trend for HMDs is to improve display resolution and increase FOV, with the goal of matching the limits of the human visual system. This means we can expect foveated rendering to become much more important. We expect the high-acuity regions to get relatively small compared to the rest of the display, and the spatially downsampling factor in the periphery to get more and more extreme.
Another parameter that significantly affects the performance of specific foveated-rendering techniques is the approach to foveation. As Guenter et al.4 have shown, there may be perceptible artifacts that get introduced from different foveation techniques. These artifacts become more perceptible when a temporal change occurs in the scene due to viewer movement or scene content. The next section reviews some of the general artifacts one has to be aware of when designing a foveation algorithm.
Human Visual System and Visibility of Artifacts: Local Contrast: To simulate lower visual acuity in peripheral vision, one may apply a blur across the frame that scales with the radial position from the fovea. Our visual system perceives a sense of tunnel vision when viewing the peripherally filtered content due to loss of local contrast in the blurred region. This sensation is perceptible even though the blurred output has the same spatial bandwidth as the periphery of the human eye. Patney et al.5 have shown that despite having lower visual acuity in the periphery, the human visual system preserves perception of local contrast. Thus, loss of local contrast needs to be avoided, or the local contrast has to be recovered. Contrast enhancement techniques exist that have been shown to significantly reduce the sensation of tunnel vision.5 However, these techniques may come with additional challenges:
1) a more sophisticated up-sampling technique that may be more expensive, and
2) techniques that do not address temporal artifacts and may require more sophisticated post-processing.
Bit depth: Although the local contrast-sensitivity of the human visual system is fairly stable in the periphery, gray-level discrimination (which is analogous to bit depth) drops quickly, and one can take advantage of this phenomenon. However, it is important to make sure that lower bit-depth rendering does not result in any quantization banding or other spatial artifacts, or any changes in color.
Temporal sensitivity: The human visual system is quite sensitive to temporal phenomena in the periphery. Thus, when designing any foveation technique, we need to be careful not to introduce what appear as temporal artifacts when there is a change in the content. Change in content may be due to animation, head motion, eye motion, or even body motion.
There are several techniques for rendering content for foveal and peripheral regions, but generally they fall into two categories:
(1) techniques that try to hide artifacts that are created in the periphery, and
(2) techniques that try to prevent the creation of artifacts.
Foveated Rendering and Artifact Correction: This category of foveated rendering techniques aims to simulate a drop in acuity in the visual system from fovea to periphery by rendering peripheral content to a smaller framebuffer resolution and then resampling it using a range of temporal and spatial upscaling algorithms. If the upscaling algorithm does not take into account aliasing artifacts, unintended motion artifacts may be introduced when the viewer moves her head and the aliasing moves in position
with respect to the original contents.
In this category of foveated rendering, one may attempt to blur aliasing, reducing the perceptibility of introduced temporal artifacts. As mentioned earlier, the anti-aliasing techniques should be aware of local contrast loss during the operation. Patney et al.5 have proposed an edge-enhancement process in the periphery to recover loss of local contrast. They have shown the proposed solution reduces perception of tunnel vision noticeably. However, the algorithm may not map efficiently to existing mobile SoC hardware architecture and would therefore require more compute cost.
Another technique is based on simulating gradual reduction in resolution by breaking down the rendering buffer into smaller regions. By introducing spatial downsampling in a piecewise-linear manner, each block of foveated regions can have constant spatially downsampled content. In addition, the multiregion process enables a gradual introduction of the
artifacts related to foveation by pushing more aggressive foveation to farther out in the peripheral region. Figure 5 shows an example of a multiregion-rendered foveation buffer.
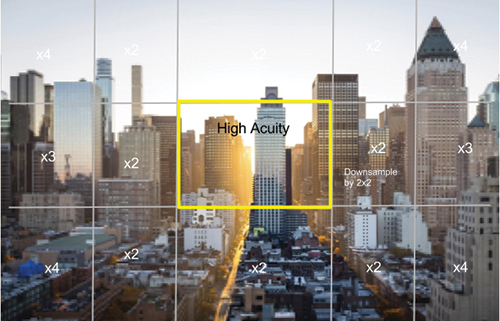
Fig. 5: The above example of multi-region foveation shows the highest-resolution sector in the area of high acuity (center).
There are several challenges to this approach, including a need to draw content at multiple steps, causing a resource-intensive operation through the graphics API. Another point to consider is the transition between the boundaries and how one may try to blend them both temporally and spatially.
Another approach is to use previously rendered frames to predict and reduce introduced motion artifacts with minimum loss in local contrast.
Temporal anti-aliasing (TAA) is a common method for smoothing the animation in a scene by averaging the pixel colors of the current frame with that of the previous frame. However, since VR head movement causes extreme rotations, this method produces ghosting artifacts. To reduce ghosting, the previous frame’s output image is reprojected to correct for the net head rotation that occurred from the previous frame. Karis et al.6 proposed a reprojection method with reduced space complexity cost. Figure 6 shows the general structure of the algorithm.
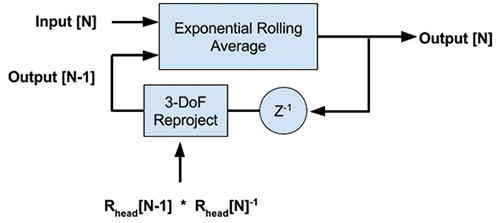
Fig. 6: This temporal anti-aliasing uses 3-degree-of-freedom (3-DoF) reprojection.
Some ghosting artifacts still exist, since this reprojection does not correct for 6 degrees of freedom (6-DoF) movement by the user or animation in the scene. The remaining ghosting artifacts are reduced by clamping outlier color values.
The clamping operation works as follows: For each pixel <i,j>, before blending the previous frame’s color Cij[N–1] with the current frame’s color Cij[N], we check how close Cij[N–1] is in value to the neighborhood around Cij[
N].
If Cij[N–1] is more than StdDev[Neighborhoodij[N]] from Mean[Neighborhoodij[N]], then the blending is aborted, and only the current frame’s color is used for this pixel.
This threshold is applied in each component of the YCoCg7 color space of the pixels.
Foveated Rendering and Artifact Prevention: The general techniques used in this category spring from understanding the root cause for perceptibility of an artifact and then attempting to remove what makes the artifact perceptible.
Phase-Aligned Rendering: One general approach in this category focuses on interaction between motion and aliases generated by rendering content in the periphery at lower resolution. One may consider this algorithm by looking at how information is presented in the real world. If we look at a real-world object with high-frequency edges, we do not perceive temporal information other than what exists in the subject. The proposed method looks at why high-frequency content in the world does not introduce a temporal artifact and applies the learning to rendering techniques.
With traditional foveated rendering, the frustums of both the low-acuity and high-acuity regions are updated with head-tracking information (and the high-acuity region can be further updated if eye tracking is available). Any artifacts generated by aliasing due to upsampling the low-acuity region will be aligned to the display coordinate system. Since the display is moving with respect to the virtual world content, aliasing artifacts will be moving relative to the content, causing artifacts that move independently of the content.
Instead, we want to enforce the low-acuity regions to be world-aligned. Then these world-aligned screens are reprojected and resampled onto the final display surface. This method means the phase offset between the low-acuity pixels and the native-resolution pixels are dynamic from frame-to-frame, always ensuring each low-acuity pixel is phase-aligned with the virtual world content (hence the name). In other words, the low-resolution sampling occurs in world space, and the artifacts are mostly invariant to head pose.
With this method, both aliases and original high-frequency content continue to exist in the scene but do not produce motion artifacts. This technique may take advantage of presenting the world in a projected space such as a cube map,8 which makes it simpler for rendering and re-projection of certain features in the scene. This kind of representation may have an additional cost due to re-rendering the world at multiple viewports, which results in multiple draw calls. Draw calls are often resource-intensive, causing performance overhead on both the central processing unit (CPU) and general processing unit (GPU). Multiview projections are typically used to reduce CPU cost for multiple draw calls per frame. Several multiview operations have been developed, with some fully supported on mobile SoCs.
Conformal Rendering: Another approach for foveated rendering is to render the content in a space that matches our visual acuity and thus not introduce artifacts related to existing rendering pipelines to start with. Such techniques can be fast, single-pass methods that could be used for both photographic and computer-generated imagery. An important feature of such techniques is that they are based on a smoothly varying reduction in resolution based on a nonlinear mapping of the distance from the fixation point. This avoids the tunnel-vision effect that has plagued previous foveated-rendering methods. The single-pass method relies on standard computer graphics GPU-based rendering techniques; hence, it is computationally very efficient and requires less time than would be required to render a standard full-resolution image.
The proposed foveated-rendering method is based on:
(i) performing a 2D warp on projected vertex positions,
(ii) rasterizing the warped image at a reduced resolution, and
(iii) unwarping the result. All these operations are carried out on the GPU of the SoC. The unwarping step can be combined with other fragment operations into a single pass operation and thus be inexpensive.
In addition to reducing image storage requirements, such foveated rendering also reduces the computational load. Less computation is required because the reduced resolution used for the warped image means that fewer pixels need to be processed by the expensive rendering shaders that compute lighting and texturing. Speed-up ratios of at least 4:1 have been obtained for standard FOV images where the content does not have many vertices. Since this method may require additional vertex creation in order to run warp operation accurately, it may not have the desired performance gain on small FOV displays with vertex-heavy content.
Steps Toward a Standard API for Foveated Rendering: Several different techniques exist for foveated rendering. Some of these methods take advantage of specific hardware features, and some take advantage of knowing how the rendering application presents content. Hence, the effort around foveated rendering has been fragmented.
To make the process more unified, a technique may need to know information about the content coming in and should have access to manipulate certain parameters in rendering, such as viewing angle or FOV of the content. The unified effort should also consider how foveated rendering interacts with the rest of the pipeline, including foveated image
processing and foveated transmission (Fig. 7).
It is desirable to have a standard API for foveated rendering. One effort led by the Khronos9 OpenXR committee aims to bring a standard extension for foveation techniques, thus enabling a language where a set of techniques can work together.
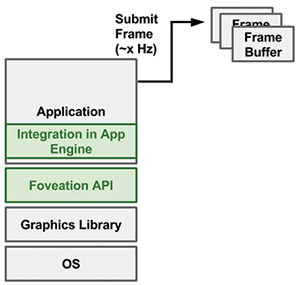
Fig. 7: In a system architecture for standard API for foveation, a unified API is presented to the application or 3D engine, and thus the complexity of the foveation techniques is abstracted out. Green areas represent the expected changes, where an API abstracts out the foveation techniques and application engines opt-in to use the API.
Foveated Image Processing
Foveated image-processing techniques include processes that improve visual quality of the rendered image. Operations that fall in this category include local tone mapping, HMD lens distortion correction, and lighting blending for mixed-reality applications.
The traditional image-processing operations run the same set of kernels on all pixels. A foveated image-processing algorithm may have different kernels for different foveation regions and thus reduce computational complexity of the operations significantly.
As an example, lens distortion correction, including chromatic aberration correction, may not require the same spatial accuracy for optical corrections. One can run such operations on foveated content before upscaling, as shown in Fig. 8.
The lens-correction operation is applied in a foveated space and then the foveated buffers are merged together as a single operation. Since lens distortion is another stage that operates on rendered pixels with a given spatial discretization, it can add inaccuracy in values. The merge operation can play an important role, and for certain foveated rendering techniques, this merge operation may combine several operations into a single step, thus reducing both compute and inaccuracy in the pipeline. The result can be perceptible for high-frequency content such as text.
Another point worth highlighting is the ability to access intermediate content of foveated rendering before upscaling. One advantage, as previously mentioned, is foveated lens distortion. In the next section we present another gain for such operations.
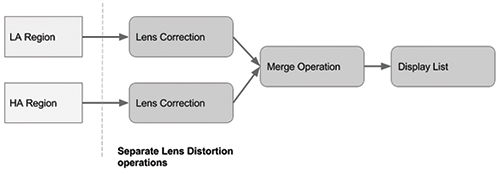
Fig. 8: In foveated image processing, various operations run separately in the low-acuity (LA) and high-acuity (HA) regions.
Foveated Transmission
In a standalone HMD system, one non-trivial but sometimes ignored source of power consumption is the data transmission over certain physical layers (PHY) between the SoC and the display module. Based on a conservative estimate, each payload bit takes around 10 pico joles to be transmitted through a mobile industry processor interface (MIPI) PHY10 to the display. This means that even for a relatively low-resolution system with QHD resolution (2,560 × 1,440 pixels), transmission of bits can cost around 50 mW, which could represent up to 10 percent of the power consumption of the HMD’s display subsystem.
This cost can become a noticeable portion of the overall power consumption of the display system and the cost increases proportionally with display resolution and frame rate. As the bits/second that need to be transmitted increase, more MIPI lanes need to be allocated to the system, which may introduce other constraints such as in the overall mechanical design of a headset.
Foveated rendering saves compute by rendering most of the displayed image at a low spatial resolution (the LA region). This region has to be upscaled to the spatial resolution of the display and blended with the small high-acuity foveal region (the HA region) to form the final image for the display. Foveated transmission sends the native LA and HA data across the link and does the upscaling and blending operations on the display side. This saves power and bandwidth by minimizing the amount of data sent across the PHY.
Under this foveated transmission scheme, the transmitted data rate is greatly reduced. In most foveation systems, the foveated data package (high acuity + low acuity) saves a considerable number of the bits for a full-resolution framebuffer. This corresponds to 60 to 90 percent power reduction in the transmission process. In addition, we expect the hardware upscaling and blending to be more efficient on the display side compared to performing these operations on the GPU in the mobile AP SoC.
There are compression techniques such as stream compression (DSC)11 that are widely adopted in the display industry. Such in-line compression methods can further reduce the data transmission rate. DSC is a visually lossless compression method that saves up to 67 percent (75 percent for ADSC) of data to be transmitted. With a carefully engineered design, one may combine DSC operation with foveated transmission and further reduce the transmission data to 2.5 percent of the original, potentially saving close to 95 percent of transmission power. Special bit manipulation may be required to maintain the visual quality of DSC while transmitting content in a foveated manner.
Toward a New Pipeline
In summary, the traditional rendering pipeline used in today’s common HMD architectures needs to be re-architected to take advantage of the unique attributes of the human visual system and deliver a great visual experience for VR and AR standalone HMDs at the low compute and power budgets available in mobile systems. The solution is a “foveated pipeline” that delivers a perceptually full-resolution image to the viewer by sending native resolution image data to the specific portion of the display at which the eyes are looking and low-resolution elsewhere, thereby saving on processing, storage, and power. In this article, we discussed three parts of the full content-creation-to-final-display pipeline that can be foveated. The pipeline can be made very efficient if the main elements of the system, i.e., the processing, optics, electronics, and panel, are optimized together. This has been an active area of research for many years and it seems reasonable to expect the appearance of VR and AR headsets with foveated pipelines in the next few years.
References
1G. Osterberg, “Topography of the layer of rods and cones in the human retina.”Acta Ophthalmologica Supplement 6, 1–103, 1935.
2D. Purves, G.L. Augustine, D. Fitzpatrick, et al., editors, “Types of eye movements and their functions,” Neuroscience, 2nd edition, Sinauer Associates, 2001.
3K. Koch, J. McLean, R. Segev, M. Freed, M. Berry, et al., “Calculate how much the eye tells the brain,” Current Biology, 16(14), 1428–1434, 2006.
4B. Guenter, M. Finch, S. Drucker, D. Tan, J. Snyder, “Foveated 3D graphics,” ACM Transaction of Graphics, 2012.
5A. Patney, M. Salvi, A. Kim, A. Kaplanyan, C. Wyman, et al., “Towards foveated rendering for gaze-tracked virtual reality,” Proceedings of ACM SIGGRAPH Asia 2016.
6B. Karis, “High-quality temporal supersampling,” Advances in Real-Time Rendering in Games, SIGGRAPH Courses 2014.
7“YCoCg,” Wikipedia, https://en.wikipedia.org/wiki/YCoCg
8“Cube mapping,” Wikipedia, https://en.wikipedia.org/wiki/Cube_mapping
9www.khronos.org
10www.mipi.org
11F. Walls, A. MacInnis, “VESA Display Stream Compression: an overview,” SID International Symposium, 360–363, 2014. •
Behnam Bastani is an engineering manager for rendering investigation at Google’s Daydream team. He can be reached at bbastani@google.com. Eric Turner is a software engineer for Google’s Daydream team. Carlin Vieri has worked on various display projects as a hardware engineer at Google since 2013. Haomiao Jiang is a software engineer for Daydream at Google. Brian Funt is a professor of computing science at Simon Fraser University where he has been since 1980. Nikhil Balram is head of display R&D for VR and AR at Google. He is an SID fellow and Otto Schade Prize winner.