Advances in 3D-Sensing Technologies and Applications
Advances in 3D-Sensing Technologies and Applications
3D sensing enabled by depth-imaging technologies allows immersive user interfaces and life-like interactive experiences via real-time understanding of the 3D environment, people, and objects in real-world scenes. Advances in this area are being made possible through several key technologies,
including sensors, algorithms, and system integration.
by Achintya K. Bhowmik, Selim BenHimane, Gershom Kutliroff, Chaim Rand, and Hon Pong Ho
RECENT developments in depth-imaging technologies and 3D computer-vision algorithms are allowing efficient and
real-time acquisition, reconstruction, and understanding of the 3D environment,
which in turn are enabling an array of new applications based on life-like
machine vision. These applications include immersive and interactive gaming, video conferencing
with custom backgrounds and synthetic environments, education and training,
virtual home and office decoration, virtual clothes fitting, autonomous
machines, and numerous other entertainment and productivity usages that
incorporate natural and intuitive interactions.
This article discusses the advances in key technologies, including sensors,
algorithms, and system integration, that are fueling the recent proliferation
of 3D-sensing applications. Specific topics include depth-sensing and tracking technologies, 3D imaging and
reconstruction, 3D gestural interactions with hand skeleton tracking,
background segmentation, and collaborative augmented reality.
Depth Sensing and Tracking Technologies
The recent availability of small form factor, low power, and real-time
depth-image-capture technologies is a key enabler for mainstream devices and
systems with 3D-sensing capabilities and interactive applications. Conventionally, vision-based applications have used 2D image sensors, utilizing
the cameras that are already part of mobile devices such as smartphones,
tablets, and laptops. These conventional image-acquisition devices are able to convert the visual
information in a 3D scene into a projection of 2D arrays of discrete numbers. As a result of this transformation process, the 3D information cannot be
accurately recovered from the captured 2D images because the pixels in the
images preserve only partial information about the original 3D space.
Reconstruction of 3D surfaces from single-intensity images is a widely researched subject. However, recovering 3D spatial information from 2D projections possesses
inherent ambiguities. Moreover, this type of approach is generally computing intensive and often
requires manual user inputs; hence, it is not suitable for applications that
require real-time and unaided understanding of the 3D environment and
interactive usages.
In contrast, the human visual system incorporates a binocular imaging scheme and
is capable of depth perception. These capabilities allow us to understand, navigate, and interact in our 3D
environment with ease. Similarly, natural and interactive experiences with vision-based schemes are
better accomplished using 3D image-sensing devices, which can capture depth or
range information in addition to the color values for a pixel, thereby allowing
fast and accurate reconstruction and understanding of the 3D world. Interactive devices and applications utilizing real-time 3D sensing are rapidly
gaining adoption and popularity.1 Examples include personal computers and mobile devices using Intel’s RealSense cameras, and gaming console systems such as Microsoft Kinect in living rooms. Figure 1 shows a pair of depth and color images captured with the RealSense 3D Camera.
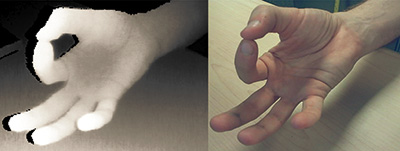
Fig. 1: Shown at left is the output from a 3D imaging device, with depth mapping that
shows nearer points as brighter. At right is the corresponding color image.
Besides the advances in image sensing, vision-based tracking and mapping techniques have progressed significantly with the advent of visual simultaneous localization and mapping approaches or visual SLAM,2–4 which allow real-time construction and updating of a spatial map while simultaneously tracking features within the environment. This is often built on top of standard 2D imaging devices to allow real-time camera pose estimation and a sparse reconstruction of the environment. In this type of representation, the object and scene surfaces are not recovered. These approaches provide limited applications because they only open up the possibility of restricting interactions to the knowledge of the camera pose.
Other visual SLAM approaches built on top of standard 2D imaging devices have been proposed and achieve denser reconstruction, but require high-end desktop
computers because of high computational demand5 or provide low-density reconstruction.6 Using 3D-imaging cameras allows real-time camera pose estimation and a dense reconstruction of the environment. With 3D-imaging cameras, simultaneous localization and dense mapping have already been shown on high-end desktop computers using rather large-form-factor RGB-D camera systems such as the Microsoft Kinect and where the implementations were processed on powerful discrete graphics processing units.7 Note that these cameras, in the best cases, require a special mount in order to be fitted on tablet form factors.8 This can result in additional costs, calibration, and grip/handling limitations that also restrict the application experiences. In contrast, the RealSense camera system provides RGB and depth data that can be embedded into a mobile device such as a tablet or a phone. Having a small form factor and low-power 3D-imaging camera system integrated in a mobile device such as a laptop, tablet, 2-in-1 device, or smartphone allows new interaction experiences (Fig. 2).
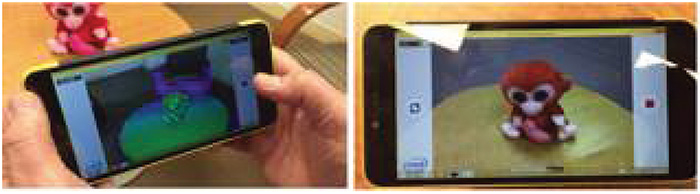
Fig. 2: The RealSense camera can be integrated within a phablet.
In conjunction with the small-form-factor computing devices incorporating 3D-sensing technologies, the Intel RealSense platform provides frameworks for algorithm implementations including scene perception based on real-time pose estimation and dense 3D reconstruction of the environment, which can be used across heterogeneous platforms (CPU/GPU) running in OpenCL kernels. These frameworks open up new types of applications that increase the interactivity between the users and the environment. For example, augmented-reality applications, among others, can make use of virtual content seamlessly added to the live camera input at an interactive
rate, and occlusions of the augmentations by real objects can be correctly handled. The motion estimation is correctly scaled and the metric measurements of the
scene are possible as well. Also, the parallel dense reconstruction allows an increase in the realism of the experience, thanks to physics and lighting simulation.
3D Imaging and Reconstruction
3D imaging and reconstruction are classic topics in computer vision. Early work focused on inferring 3D models from lines and corners, followed by
work on stereo matching and multi-view stereo.9 As digital-imaging hardware progressed, it made it possible to create dense 3D depth maps in real time, which led to advancements in robotics, computer graphics, and image analysis. A natural question that emerged was whether the depth images could be fused together to form a 3D model, provided there was a way of determining the pose of the camera for each image. Early methods focused on space carving and point-cloud representations because the devices were either tethered, low frame rate, or low resolution. Therefore, only thousands of depth measurements could be used to construct a model. However, approaches for 3D reconstruction have been revisited in recent years to
address bandwidth challenges of dense high-frame-rate 3D-imaging devices mounted on handheld devices. Intel’s RealSense camera is capable of capturing millions of depth samples per second in an unrestricted workspace.
To efficiently process and use as much of the depth data as possible to form a 3D model, voxel representations are popular because the voxel grid data structure is very efficient for accumulating information in 3D space. It also allows multiple accumulations to occur in parallel without memory contention in different regions of space, which is amenable for GPU or multicore CPU processing.7 The drawback to voxel representations is that the workspace has to be known in advance to enable real-time reconstruction, and the amount of memory needed to reconstruct an object scales cubically with resolution, even though the surface area of the object scales quadratically (two dimensionally). For instance, a 1-m cubed space that is to be reconstructed at 2-mm resolution requires a memory block for 125 Mvoxels, even though for a closed object, the surface of the object will occupy ~1 Mvoxels, which means 99.2% of the memory will go unused (wasted). To address the data space inefficiency of voxel grids, hierarchical techniques have been developed to increase the grid resolution where there are more samples,10 along with variants that are more appropriate for GPU architectures.11
These methods reduce the memory requirements to be quadratic and in line with the amount needed to represent the surface as a triangle mesh. Figure 3 shows a real-time 3D reconstruction using the RealSense technology.

Fig. 3: Real-time 3D scanning and reconstruction are demonstrated with (left) a tablet equipped with an embedded RealSense camera used to scan a real-world scene. The middle image is the 3D scanned version. At right is the same image including texture mapping and color information.
Hand Skeleton Tracking
Real-time hand skeleton tracking capability is necessary for implementing 3D user interfaces supporting fine-grain manipulation of virtual objects with finger-level gestural articulations. This is a challenging problem, due to its high dimensionality, the prevalence of self-occlusions, the rapid movements of the fingers, and the limited viewpoint of a single camera. Moreover, in the case where skeleton tracking enables gesture control for interactive applications, user expectations of robustness and continuity of experience place high demands on the quality of the solution. False positives and unpredictable behavior due to erratic tracking are liable to quickly exhaust the user’s patience.
One approach with the potential to handle the complexities of human-hand articulations is known as synthesis-analysis. In this technique, the skeleton joints of a 3D articulated hand model are transformed according to a search optimization algorithm, and then the hand model is rendered and compared to the data captured by the camera. The process is repeated for as long as the rendered data do not match the camera data or until there is convergence. When there is a match, the pose of the model is assumed to be correct and the skeleton’s articulation to be found.
Synthesis-analysis approaches have been applied to various problems in computer
vision, such as tracking facial expressions12 and object recognition.13 However, there is a clear benefit in applying this technique to 3D camera data
as opposed to 2D images. In particular, with 2D images, the effects of shadows, lights, and varying materials all must be factored into the synthesized render. Figure 4 displays an RGB image as captured, adjacent to an unshaded render of a 3D hand model. With some effort, multiple layers of effects can be added to the rendering pipeline in order to produce a rendered 3D model that more accurately resembles the image captured by the camera. In Fig. 4, we see that the end result is reasonably close to the image captured by the camera. However, the complexity of this pipeline means it is difficult to design texture maps and shading scales sufficiently general to handle the full range of users’ skin colors and characteristics. Moreover, appropriate lighting models must be extracted from general scenes, and the entire pipeline must run in real time, through several iterations per frame.
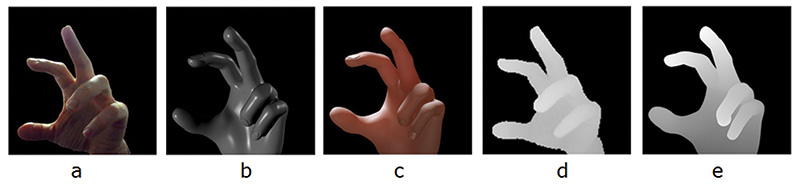
Fig. 4: The 2D image data appears in (a); (b) is the unshaded rendered model; and (c) the model with texture, shading, treatment for fingernails, and lighting. The depth map appears in (d) and (e) shows the rendered depth map.
By contrast, when displaying a depth map of the hand as captured by a 3D camera adjacent to a single pass of a depth map as rendered from the same 3D hand model, the resemblance between these two images is quite strong. Moreover, rendering a depth map can be easily performed on the GPU to accelerate the real-time performance of the algorithm.
In this way, the availability of real-time depth data allows for the implementation of a synthesis-analysis technique that enables real-time robust hand skeleton tracking, providing the level of tracking required to drive intuitive, immersive, and natural experiences. The hand skeleton tracking solution available in the RealSense SDK relies on a synthesis-analysis approach to derive the full articulation of the skeleton and runs at 30% of an Intel 5th Generation Core i5 CPU, at over
30 frames per second (fps).
Background Segmentation
The identification of object boundaries has long been a core research topic in computer vision. Classical color or intensity-based segmentation techniques spanning from edge detection, pixel classification, shape/texture modeling, combinations of the above, and others have been proposed.14,15 The distortion introduced during image formulation makes boundary delineation from color data difficult. Small differences make general-purpose edge detection very challenging and that is without considering lighting and motion distortion. Region-based techniques such as texture analysis could be less sensitive to subtle capturing variations; however, they often rely on expensive or restrictive prior knowledge, and it is difficult to cover a wide range of targets robustly in one system.
With RGB-D sensing technology such as RealSense on a system such as a laptop computer, we can reformulate the intrinsically ill-posed segmentation problem in a robust and practical way. First, the additional depth information provides an excellent engineering prior knowledge, as we can easily obtain a good initial estimate of foreground and background pixels in real time. Second, an integrated camera system allows efficient alignment between color and depth image that brings the initial estimate to the color image for the segmentation process. Third, with enhanced 3D face detection enabled by real-time depth-sensing technology, the recovery of relatively problematic target structures, e.g., hair, can be achieved by a new formulation incorporating color, depth, and position relative to the face.
As an illustration of practical usage of background segmentation, we show a background replacement example in Fig. 5.

Fig. 5: Left: Real-time user segmentation of integrated RGB-D data stream enables enhanced video-collaboration experiences. In the center image, a boy is pictured in front of the original background, and, at right, against a synthetic background.
Collaborative Augmented Reality and Other Applications
Collaborative augmented reality (AR), with a host of possible real-world uses, is one of the most immediately appealing applications that can be realized through the latest depth-imaging technology. Figure 6 depicts two AR usages. The left image shows a virtual decoration of a room in which real-world objects (e.g., the sofa) are intermingled with digitally rendered objects (e.g., the lamp). Note the geometric correctness of the perspectives and consistent shadows and shades. The right image shows an immersive gaming application in which a virtual car is rendered on a physical table that interacts with other real-world objects.

Fig. 6: Examples of augmented-reality applications include virtual room arranging at left and gaming with a virtual car at right.
When workers collaborate on projects, they often find it useful to share, visualize, and interact with the same digital information. Similarly, outside of work, many people relax by playing collaborative or competitive games with others. Collaborative AR builds on scene perception to enable and enrich such interactions. Users can enter an environment with depth-camera-enabled devices, automatically discover fellow workers or players, and seamlessly connect to them to enter a shared physical-digital interaction space. Each device reconstructs the environment around it, and all devices in the interaction space initially calculate then track their pose relative to the same origin in 3D space by using natural features of the scene and putting them into the same coordinate system. This enables any rendered graphical content to appear to be placed in exactly the same physical location for all users.
One example of a collaborative AR application is room re-decoration. Two users start the application, see each other on the network, and connect. As they move the devices around to look at different areas of the room, they reconstruct a digital representation that is shared across both devices. The users can drag and drop 3D furniture models (such as a sofas, tables, and lamps) into the scene, then move and re-orient the models. The furniture appears realistically integrated with the real-world camera view, with correct occlusion of real-world objects and with shadows. As they interact, users see each other’s changes reflected on their devices; hence, they can discuss and collaboratively arrange the furniture until both are happy with the layout (see Fig. 7).

Fig. 7: In this example of collaborative AR, users move virtual furniture to decorate a room together.
Head-mounted displays (HMDs) are another possible application. While depth cameras enable sensing, tracking, reconstruction, and interaction in 3D, conventional display devices such as monitors, tablets, phones, or projectors are limited to 2D image displays. We can enable a matching output fidelity and have users be more immersed in virtual content by making use of HMDs in both virtual-reality (VR) and AR scenarios.
Depth data also opens the door to a world of new and enhanced photography and videography capabilities. This data enables features such as changing the depth of field of a captured image, applying artistic filters to specific portions of the picture such as the foreground or background, enhanced editing based on depth information, applying motion effects such as parallax, and more.
The Future of 3D Imaging
The low power and small form factor of the 3D depth imaging provided by RealSense technology allows a 3D sensing camera to be nearly anywhere – on handheld, wearable, and mobile computing systems ranging from HMDs, laptops, 2-in-1 devices, tablets, or even phablets, in addition to desktop and stationary computing systems and kiosks. The immersive applications that benefit from it include interactive or collaborative usages such as gaming, virtual home and office decoration, video
conferencing with custom backgrounds and synthetic environments, virtual clothes fitting and shopping, 3D scanning, etc. In addition to these, real-time 3D sensing and visual understanding will also enable autonomous machines that can interact with humans naturally and navigate in the 3D environment.
We believe that a trend of moving from 2D imaging to depth imaging and 3D sensing using RealSense will allow original equipment manufacturers to differentiate their products. In addition, the free Intel RealSense Software Development Kit (SDK) will encourage independent software vendors to develop various applications in
gaming, education, and training, providing novel and innovative experiences.16 Mobile computers with integrated RealSense technology are already available in the marketplace from a number of system makers.17 Interactive and immersive software applications built using the RealSense SDK are also increasingly becoming available from an array of application developers.18 Beyond the conventional computing devices, autonomous machines such as robots and drones have also been demonstrated that have the ability to understand and navigate in the 3D world with RealSense technology.19,20
The future of interactive and immersive computing enabled by 3D visual sensing and intelligence is exciting, and that future is already here!
References
1Interactive Displays: Natural Human-Interface Technologies, A. K. Bhowmik, ed. (Wiley & Sons, 2014).
2A. J. Davison, I. D. Reid, N. Molton, and O. Stasse, “MonoSLAM: Real-Time Single Camera SLAM,” IEEE Trans. Pattern Anal. Mach. Intell. 29(6),1052–1067 (2007).
3G. Klein and D. Murray, “Parallel Tracking and Mapping for Small AR Workspaces,” IEEE ISMAR (2007).
4G. Klein and D. Murray, “Parallel Tracking and Mapping on a Camera Phone,” IEEE ISMAR (2009).
5R. A. Newcombe, S. J. Lovegrove, and A. J. Davison, “DTAM: Dense Tracking and Mapping in Real-Time,” IEEE International Conference on Computer Vision (2011).
6J. Engel, T. Schöps, and D. Cremers, “LSD-SLAM: Large-Scale Direct Monocular SLAM,” ECCV (2014).
7R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davison, P. Kohli, J. Shotton, S. Hodges, and A. Fitzgibbon, “KinectFusion: Real-Time Dense Surface Mapping and Tracking,” IEEE ISMAR (2011).
8http://structure.io/
9R. Hartley and A. Zisserman, Multiple View Geometry in Computer Vision (Cambridge University Press, 2004).
10F. Steinbrucker, J. Sturm, and D. Cremers, “Volumetric 3D Mapping in Real-Time on a CPU,” IEEE ICRA (2014).
11M. Niessner, M. Zollhoefer, S. Izadi, and M. Stamminger, “Real-time 3D reconstruction at scale using voxel hashing,” ACM Transactions on Graphics 32(6) (2013).
12E. Peter and B. Girod, “Analyzing facial expressions for virtual conferencing,” IEEE Computer Graphics and Applications 18.5, 70–78 (1998).
13H. Mohsen and D. Ramanan, “Analysis by synthesis: 3D object recognition by object reconstruction,” IEEE CVPR (2014).
14T. F. Cootes, C.J. Taylor, D.H. Cooper, and J. Graham, “Active Shape Models – Their Training and Application,” Computer Vision and Image Understanding 61, No. 1, 38–59 (1995).
15G. Doretto and S. Soatto, “Dynamic Shape and Appearance Models,” IEEE Transactions on Pattern Analysis & Machine Intelligence 28, No. 12, 2006–2019 (2006).
16www.intel.com/realsense/developer
17www.intel.com/realsense/devices
18appshowcase.intel.com/realsense
19www.wired.com/2015/08/intel-giving-devices-senses/
20www.theverge.com/2015/1/6/7505803/intel-realsense-technology-can-make-every-device-self-aware •
Achintya K. Bhowmik, Selim BenHimane, Gershom Kutliroff
, Chaim Rand, and Hon Pong Ho are with Intel Corp. in Santa Clara, California. Achin Bhowmik can be reached at achintya.k.bhowmik@intel.com.