Head-Mounted-Display Tracking for Augmented and Virtual Reality
Head-Mounted-Display Tracking for Augmented and Virtual Reality
Head-Mounted-Display Tracking for Augmented and Virtual Reality
Head tracking is a key technical component for AR and VR applications that use head-mounted displays. Many different head-tracking systems are currently in use, but one called “inside-out” tracking seems to have the edge for consumer displays.
by Michael J. Gourlay and Robert T. Held
IN 2016, several head-mounted displays (HMDs) reached the consumer marketplace, providing users with the ability to augment the real world with digital content
and immerse themselves in virtual worlds. A key technical component for this is “head tracking.” Tracking estimates the pose (orientation and sometimes position) of the HMD relative to where it has been in the past. Having that pose permits synchronization of a virtual camera with real-world head motion, which in turn allows virtual models (holograms) to appear as though they are locked to the world. This article provides a brief overview of how most tracking systems work, with a focus on technologies in use in contemporary HMDs.
Tracking Overview
Head position can be represented by the position along three head-centered axes (X, Y, and Z in Fig. 1) and by orientation relative to those axes. Tracking can be accomplished with a variety of sensors, including inertial and visual. (Others are possible, such as GPS and magnetic, but they will not be discussed here.) Some trackers provide only orientation, which entails three degrees of freedom (DoF). They are called 3 DoF trackers. Other trackers also provide position, so they are called 6 DoF trackers.
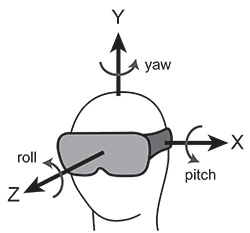
Fig. 1: The momentary position of the head is described by three position numbers: X corresponds to left-right position, Y corresponds to up-down, and Z corresponds to forward-backward (where the origin of the X-Y-Z coordinate system is the center of the head). Positional changes are described by changes in those three numbers. The momentary orientation of the head is described by rotations about the X, Y, and Z axes (where zero is normally referenced to earth-centered coordinates). Pitch corresponds to rotations about the X axis (head rotating up or down); yaw corresponds to rotations about the Y axis (rotating left or right); and roll corresponds to rotation about the Z axis (tilting the head to the side).
Inertial tracking is fast, cheap, and robust, but typically suffices only for 3 DoF tracking because the inertial tracking of position requires integration of
noisy acceleration measurements over time, which leads to a gradual accumulation of error. Visual tracking is comparatively slow and expensive but can be extremely accurate with essentially no drift. Combining these two techniques into visual-inertial tracking through “sensor fusion” yields the best of both worlds – low latency, high accuracy, and no drift – and enables high-quality augmented-reality (AR) and virtual-reality (VR) experiences.
How 6-DoF Tracking Works: Inertial and Visual Tracking
Inertial tracking involves integrating measurements from components of an inertial measurement unit (IMU), which typically contains an accelerometer (that measures linear acceleration), a gyroscope (that measures angular velocity), and sometimes a magnetometer (that measures the local magnetic field). Integrating those values can be conceptually straightforward; the mathematics would be familiar to a person who took physics, calculus, and linear-algebra classes. Integration can be used to obtain a linear velocity from linear acceleration and a position from the velocity. Likewise, orientation can be obtained from the angular velocity. Furthermore, the constant and uniform acceleration due to gravity can be used to obtain orientation in two dimensions (elevation, which is similar to pitch except it’s fixed to the earth coordinate frame, and tilt, which is roll relative to gravity) and the magnetic-field-reading relative orientation in the azimuthal direction (yaw relative to an initial direction).
In practice, inertial tracking also must handle noise, bias, and other sources of errors in IMUs and combine inertial tracking estimates with estimates obtained through visual tracking. Otherwise, the pose obtained from inertial tracking tends to drift away from the correct value (especially when using small inexpensive IMUs as used in consumer devices).
Inside-Out Tracking: Sparse Feature Tracking and Mapping
There are two major types of visual tracking: inside-out and outside-in. There are many variations within the two types. This section describes one variation of inside-out tracking and one of outside-in tracking. We also describe “lighthouse tracking,” which is similar to inside-out tracking but with some key distinctions.
Inside-out vision-based tracking is also called “ego-motion tracking,” which means that the object being tracked is the camera itself, i.e., not what the camera is looking at. The distinction is somewhat artificial because if the camera were stationary and the world were moving, the results would be visually identical. This point reflects a key aspect of visual tracking: To estimate the pose of the camera, the algorithm also needs a geometric model of the environment captured by the camera. The motion of the camera can be tracked relative to the environment, so either entity could move and have its motion tracked. If the geometry of the environment is not already known (and in most consumer situations it is not), the algorithm must simultaneously model the environment and track the camera pose. Hence, this type of algorithm is called “simultaneous localization and mapping” (SLAM) or “tracking and mapping.”a� The model of the environment could be sparse, dense, or somewhere in between the two. A sparse model consists of a collection of feature points (such as corners), whereas a dense model consists of dense regions of either scene geometry or
images. We will focus on sparse models.
Visual tracking requires accurate knowledge of the locations of feature points in the environment relative to the camera. Mathematically, an ideal camera can be modeled as a pinhole through which light rays pass. Such a camera maps light reflected off points in 3D space onto a 2D plane (Fig. 2). Such a camera can be described by the position of the pinhole and the position and orientation of the plane onto which light is projected.
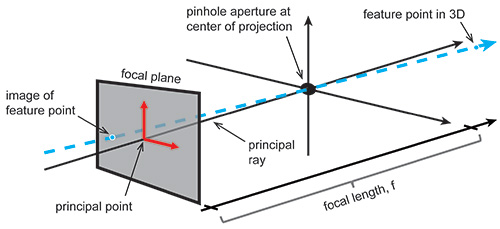
Fig. 2: This diagram shows the projection of a 3D point onto the image plane of a pinhole camera.
Real cameras have lenses that distort the directions in which rays pass through the aperture. With calibration, those distortions can be measured. That distortion can be modeled with a function and then one can “undistort” rays, after which a real camera can be effectively treated as a pinhole camera.
Stereo Triangulation
Visual trackers can use either one camera or a “rig” of cameras rigidly mounted together, some of which might have overlapping fields of view. In practice, these options are implemented in a variety of ways. For example, a “stereo rig” has two cameras with overlapping fields of view. Such a rig can be used to determine the distances of image features relative to the cameras (Fig. 3). In contrast, visual tracking with a single camera means that distances can never be determined in world units; all distances would be relative to other distances within the images; i.e., the scale is ambiguous. A tracker for which the distance of features to the camera rig is known, for example, through stereo triangulation and how that triangulation works will be described. It suffices for the following description to know that image features have a position in three-dimensional space relative to the camera, and those 3D positions can be known, from a single stereo image, with some uncertainty.
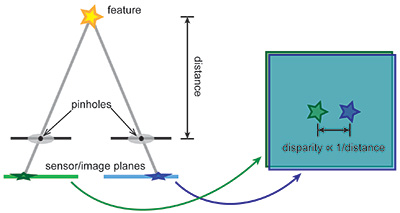
Fig. 3: Stereo triangulation uses knowledge of the relative positions and orientations of two cameras to convert a real-world feature’s disparate projections into a distance measurement.
To use a stereo rig to determine the 3D positions of features within a scene, the relative position and orientation of the camera pair need to be known. This can be done by taking a photograph of a calibration target, such as a checkerboard, that has known structure with sufficient complexity (e.g., has enough identifiable features, like corners on the checkerboard), and then solving a system of linear equations for the positions and orientations of the two cameras and the marker-board plane. Assuming the rig is rigid, this calibration can then be used to infer the 3D structure of any scene it captures.
Triangulation involves finding pairs of corresponding feature points in the images of the two cameras and measuring their disparity across the two images. In general, the differences in the positions of images from one object (i.e., the disparity) occur along a line: an epipolar line. When the cameras are parallel and horizontally displaced from one another, epipolar lines are just horizontal lines in the camera’s sensors. Thus, the search for pairs of corresponding feature points and the measurement of disparity is simpler. Even a single set of 3D features from a single stereo image pair suffices for tracking.
Tracking with a Known Map
If the 3D structure of the environment is known, the algorithm for tracking against the known map works like this:
• Start with a hypothesis for camera pose.
• Numerically project 3D points from the environment’s map into the current camera.
• Find correspondences between image features and projected 3D points.
• Compute the distance (in image space) between corresponding image features and projected 3D points.
• Minimize error with respect to pose.
Note that this tracking algorithm does not need (or even use) stereo overlap or depth information from tracking images. Tracking can be “monocular” even if the rig is stereo.
Step 1: Start with a hypothesis for camera pose. The “hypothesis” for the camera pose could be as simple as using the previous camera pose. (The initial pose is arbitrary.) The hypothesis can be made more sophisticated by assuming the camera will continue on its current trajectory; i.e., assume the camera moves according to a motion model (e.g., constant acceleration) and then predict where it is currently.
Step 2: Numerically project 3D points from the environment’s map into the current camera. Mathematically, a camera is just a function that maps 3D points to a 2D plane; i.e. “projection.” The inputs to that function include the 3D position and orientation (a.k.a. pose) of the camera relative to the 3D positions of all the points in the map. So, Step 2 entails applying that function to the 3D points in the map to synthesize a virtual image.
Step 3: Find correspondences between image features and projected 3D points. Now there are two images: The real image captured by the camera and the virtual image. The virtual camera is meant to have the same properties (e.g., pose, focal length, aspect ratio, and field of view) as the real camera. So features in the virtual image are meant to match features in the real image. Each feature point in the real image should have a corresponding point in the virtual image. Step 3 entails associating each of these pairs of points, a process called “data association.”
There are many ways to accomplish this step. Among the simplest is to assume that, for any point in the real image, the corresponding point is the one nearest to it in the virtual image. Instead, each feature can also be described in the real image with some function (like a hash), and then one can apply the same function to the virtual image and form correspondences according to this feature description. Each data-association method has benefits and drawbacks, but ultimately the outcome of Step 3 is some collection of corresponding pairs of feature points, one from the real image and one from the virtual image.
Step 4: Compute the distance (in image space) between corresponding image features and projected 3D points. Given each pair of features from Step 3, compute the distance between those features. The units could be in pixels or in the angle subtended by that distance. This error is “reprojection error.”b
Step 5: Minimize error with respect to pose. As shown in Fig. 4, the idea is to wiggle the virtual camera, trying various perturbations in position and orientation, and repeat steps 1–4 until the pose that results in the smallest reprojection error possible is determined. In principle, this could be done by brute force: try every possible position and orientation. But this takes too long to compute because pose exists in a six-dimensional space. So, in practice, a numerical model of how the error varies with each component of the pose (three translations and three rotations) can be formulated, then the reprojection error can be minimized by using some numerical optimization algorithm, such as least-squares or one of its variants such as gradient descent, Gauss-Newton, or Levenberg-Marquardt.
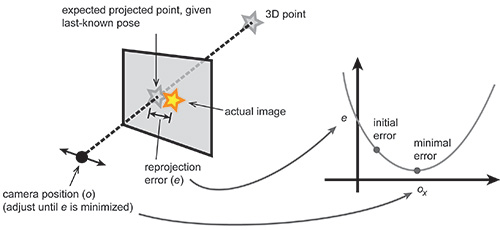
Fig. 4: New camera positions and orientations can be determined by minimizing the expected and actual projected position of a real-world 3D point.
Multiple sources of pose estimates can be combined, such as from inertial and visual trackers, for example, by using a Kalman filter. This yields the benefits – and reduces the drawbacks – of the various sources. They can be combined into a weighted running average where the weight is inversely proportional to the uncertainty of each measurement source.
Hiding Latency
The naïve way to render a virtual scene given a real camera pose would be to render the virtual scene using a virtual camera whose pose matched the latest estimate of the real camera pose. But rendering takes time, and by the time the rendered scene goes through the display pipeline and hits the user’s eyes, the pose used to render the scene is out of date. Fortunately, there is more than just the latest pose; there is also a pose history, inertial measurements, and a dynamical model (e.g., rigid body motion) to help estimate where the camera is headed. Thus, where the camera will be by the time light from the display hits the user’s eyes can be predicted. In that sense, the perceived latency can be by construction zero, as long as you know the timings involved (and they often can be measured).
But the prediction is only as good as the latest measurements, so any deviation from the motion model leads to misprediction. Users will perceive this error as jitter. But it is possible to mitigate jitter. Rendering the scene takes several milliseconds. During that time, the IMU generates many more samples, permitting a refinement of the camera-pose estimate. Because the scene has already been rendered that information might seem useless. But after, the scene (including color and depth) is rendered to a back-buffer, it is possible to transform that buffer to make it conform to the latest view. For example, if that scene is treated as though it is a picture projected onto a sphere centered on the user, then that sphere can be rotated according to how the camera pose rotated. Rotation accounts for a major portion of the motion perceived, so this solution goes a long way toward hiding the residual latency.
Lighthouse Tracking
Lighthouse tracking refers to the tracking technology developed by Valve as part of the SteamVR platform. Lighthouse tracking is a form of inside-out tracking because it uses sensors on the HMD (or any other tracked device) to determine its orientation and position. However, the system also requires the use of base stations (the “lighthouses”) that emit infrared (IR) light so it cannot work in any environment without prior setup.
Lighthouse tracking requires each tracked object to be covered with multiple IR sensors. Valve has developed software to optimize the number and placement of these sensors to ensure that the object can be robustly tracked in any orientation relative to the base stations. As discussed below, the spatial relationship between these sensors must be known by the tracking system in order to recover the object’s position and orientation.
Prior to operation, two IR-emitting base stations are fixed in locations that allow them to sweep the entire tracking volume with IR light. During operation, each base station repeatedly emits an IR flash, followed by a horizontal sweep of IR light, followed by another flash, and then a vertical sweep of IR light. The flashes occur at 60 Hz, and each one serves as a synchronization pulse. On the HMD, a timer is started as soon as each pulse is detected. Next, the times at which the ensuing IR sweep hits each sensor are recorded. The rotation and position of the HMD is computed by combining the known relative placement of the sensors, the angular speed of the IR sweeps, and the detection times of the vertical- and horizontal-sweep pulses. These positional data are fused with a high-speed IMU to produce 6-DoF poses at a rate of 1000 Hz.
Outside-In Tracking
One can also track a camera using outside-in schemes. The principles are similar to those in inside-out tracking but reversed. As mentioned above, visual tracking really only tracks the motion of the camera relative to the scene. If the cameras are stationary and the “scene” is the HMD, the same algorithms (or at least algorithms with the same underlying principles) yield a pose trajectory, which indicates how the “scene” (the HMD in this case) has moved.
Outside-in tracking has the benefit that the feature points being tracked are manufactured into the HMD, usually in the form of light emitters, so they are guaranteed to be illuminated regardless of the ambient scene, and their structure is known in advance. This setup drastically simplifies the situation, making such trackers much easier to implement.
The main drawback of outside-in trackers is that the tracking cameras and the HMD are separate devices, so the “playspace” – the region where the HMD can be tracked – is limited by the range of the fixed tracking cameras. Inside-out trackers have no such limitation because the tracking cameras travel with the device. Inside-out trackers do not require setting up external tracking cameras and permit the HMD to travel any distance.
For both inside-out and outside-in tracking, the IMU is attached to the HMD; that aspect of tracking works the same.
Inside-Out Tracking Has the Edge
Visual-inertial tracking facilitates world-locked digital content such as images and sound. Vision-based tracking includes inside-out and outside-in implementations. Both entail tracking visual targets; the difference is whether the targets are in the environment or on the HMD. Outside-in requires setting up equipment within the environment but can be simpler to implement to achieve a given accuracy target. Inside-out can track natural features and is better suited to mobile experiences, but requires more sophisticated algorithms and expensive computation. Both technologies can be found in current consumer products, but the trend seems to be toward inside-out tracking due to the simplified user experience and mobility.
Further Reading
Kalman, “A new approach to linear filtering and prediction problems,” Transactions of the ASME – Journal of Basic Engineering 82, series D, 35–45 (1960).
Horn, “Closed-form solution of absolute orientation using unit quaternions,” J. Opt. Soc. Am. A. 4, No. 4 (April, 1986).
Hartley and Zisserman, Multiple View Geometry in Computer Vision (Cambridge University Press, 2004).
Boyd and Vandenberghe, Convex Optimization (Cambridge University Press, 2004).
Klein and Murray, “Parallel Tracking and Mapping for Small AR Workspaces,” ISMAR 2007.
Szeliski, Computer Vision: Algorithms and Applications (Springer, 2011).
Valve, “SteamVR Tracking” (2011), https://partner.steamgames.com/vrtracking/ •
aTechnically, a visual tracker could estimate relative motion without retaining a map; tracking could always be relative to a previous frame. Such tracking is called “visual odometry” and has practical applications, but that concept will not be described further.
bThere are multiple subtle variations possible for precisely how to compute this, and among them only one is properly called “reprojection error,” but the details are beyond the scope of this article.
Michael J. Gourlay is a Principal Development Lead at the Environment Understanding group in Analog, the division of Microsoft that makes HoloLens, Hello, and Windows Holographic. He can be reached at mija@mijagourlay.com. Robert T. Held is a Senior Software Engineer in the HoloLens Experience Team at Microsoft. He can be reached at robert.held@gmail.com.